

こんにちは、DSOCの奥田です。
今回は、7月18日にSansanの表参道本社にて開催した勉強会「自然言語処理領域(NLP)に関わっていると避けては通れないあの話」の模様をお伝えします!
今回のテーマは「自然言語処理」です。Sansanというと、名刺管理サービスというイメージが強く、OCRなどの画像認識が取り上げられることが多いですが、実はその裏では自然言語処理の技術もさまざまな部分で活用されています。
今回の勉強会では、そういった実例を交えながら、Sansanの取り組みを紹介しました。
Eightニュースフィード活性化のための自然言語処理の取り組み
まずはDSOC R&Dグループの研究員の高橋が、個人向け名刺アプリ「Eight」のニュースフィードにまつわる自然言語処理の開発と実運用について話をしました。

皆さんはEightを使われてますでしょうか? EightはSNSとしての機能を持っており、ニュースフィードという形でニュース記事をコメントと共に流すなど、フィードに投稿することができます。ニュース記事には、文中で言及されている企業の名前をタグ付けすることができるのですが、その機能を自然言語処理の技術で解決しています。
20180718Eightニュースフィード活性化のための自然言語処理の取り組み from Kanji Takahashi
発表の中では、企業名タグ付けのプロジェクトが発足した経緯やニュースの文章から企業名を抽出するアルゴリズム、実運用におけるAWS活用など、ビジネス化する上で避けては通れない話が盛りだくさんでした。
ここでは、発表の中から一部抜粋して紹介します。
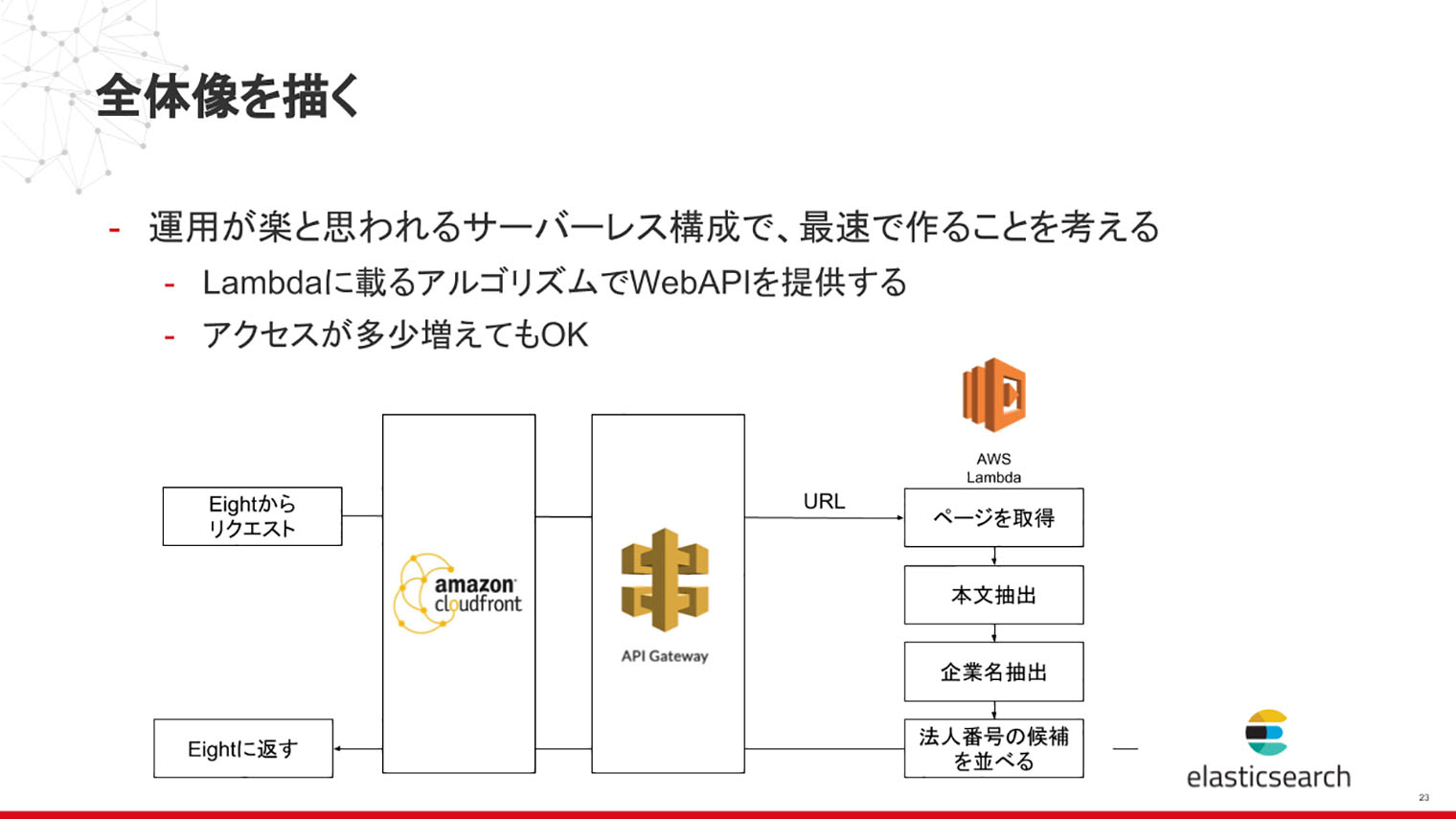
この企業名タグ付けのシステムは、現在AWS Lambdaで構築しています。Eightの裏側では、ニュースのページ内容の取得、本文の抽出、その中にある企業名の抽出、そして企業を表すIDの候補を出すという処理が走っており、それぞれに技術的に難しいポイントがあります。本文の抽出では、さまざまなニュースサイトに対応する抽出器を作る必要があったり、企業名検出ではいかに精度高く企業名を抽出できるかであったり、さまざまなアルゴリズムを検討しチューニングしています。詳しくは、前出の発表資料をご覧ください。
ちなみに、高橋のGitHubでは、本文抽出のエンジンpython-extractcontent3をOSSとして公開しています。
ニューラル姓名分割と企業における自然言語資源の活用について
続いて、同じくDSOC R&Dグループの研究員である私が、姓名分割というタスクの実験結果と、それにまつわる言語資源の活用について話しました。

勉強会で映した資料は諸般の都合により公開できないのですが、一部のスライドとともに概要を紹介します。
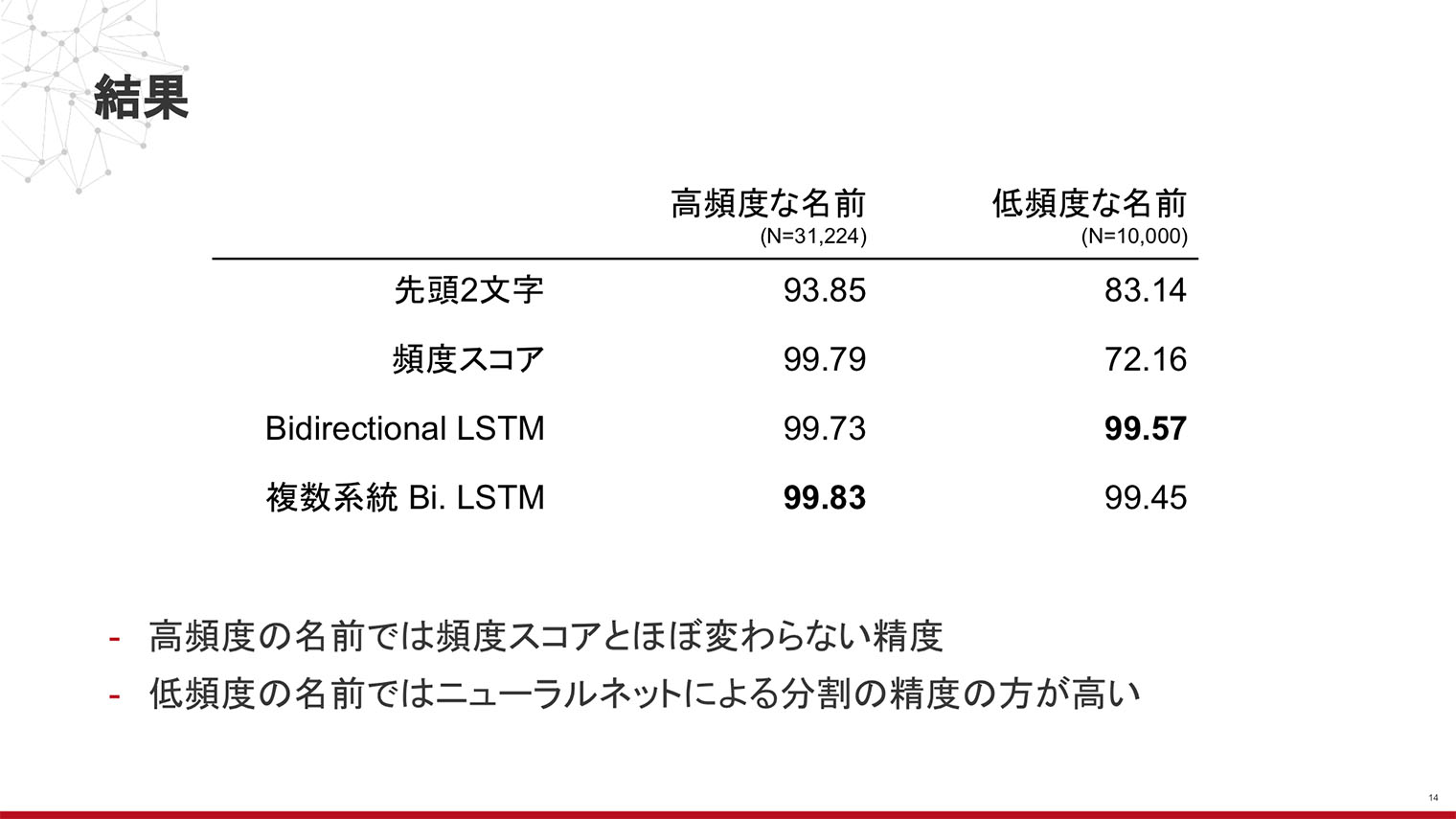
まず「姓名分割」とは、氏名がつながった文字列が与えられたときに、それを適切に名字と名前に分割するタスクのことです。例えば、「織田信長」とあったときに「織田」と「信長」に分けるといった感じです。今回は、これを頻度スコアを用いたルールベースでの分割手法、Bidirectional LSTMという構造のニューラルネットを使った分割手法など、いくつかの手法を試しながら精度を比較しました。

実験の結果ですが、2種類のデータセットによる評価において、どちらもニューラルネットを用いた分割手法が最も高い精度を示しました。よくある名前(下図の高頻度な名前)では、いずれにしても90%を超える精度を示していることから、タスク自体はかなり容易なものとなっております。
しかし、私たちSansanが扱うデータの先にはリアルな人がいます。氏名を間違えて表示してしまうなんてことは、サービスとしては避けたい事態です。99%の精度で100人に1人間違うというのでは実力としては不十分です。実運用に耐えるシステムとするには、99%の先を目指す必要があります。
また、個別のエラー分析も発表中では紹介しました。それによると、ニューラルネットはなぜか「長谷川」を「長谷」と間違えやすいということが分かりました。正確な原因はよく分からないのですが、「新谷」「中谷」といったように「谷」で終わる名字が多く、ニューラルネットはこの「谷」が来ると名字の終わりであるということを強く学習してしまったのかもしれません。
こうした分析ですが、機械学習をやっている以上、避けては通れないのが、何よりも「データ」です。自然言語処理では特にコーパスと呼ばれる言語資源に頼ることが多く、そうしたデータをいかに適正に利用するかが重要になります。Wikipediaなど明確にクリエイティブ・コモンズの表明という形で権利関係が定まっているものもあれば、さまざまなウェブサイトをクロールしたデータなど利用が制限されるものも多いという話をさせてもらいました。
その上で、Sansanでは理研AIPが主催する「森羅:Wikipedia構造化プロジェクト2018」に参加して、Wikipediaから構造化されたデータをより多く得るためのプロジェクトに協力しています。こちらも面白い取り組みになっていますので、ぜひ見てみてください。
懇親会
勉強会終了後には、懇親会が開かれました。こちらにも多くの方が参加され、発表内容に関する話や自然言語処理にまつわる議論が活発に行われていたようです!
私がお話させていただいた方からは「自然言語処理は簡単に思われることが多い。もっと自然言語処理での開発やR&Dでの事例を発信してほしい」と言った話であったり、各社さんならではの苦労話を聞かせていただくことができたりと、私個人としても非常に学びの多い会になりました。
ちなみに、私はいろいろな方と話すので精一杯で提供された食事に手がつけられませんでした……?。でも、きっとおいしかったはず!

まとめ
いかがでしたでしょうか? 今回は「自然言語処理」を題材にした、Sansanが主催した勉強会の模様を紹介しました。一般によく研究対象になる機械翻訳や文章要約、対話などの自然言語処理の領域ではありませんが、Sansanでは少し独特なデータに対して自然言語処理の知見を活用して取り組んでいます。
また、それらの他にも、画像データとの連携やさまざまなデータを突き合わせた名寄せ技術の開発など、マルチモーダルな処理にも活発に取り組んでいます。ちょっと話を聞いてみたいという方も大歓迎ですので、奥田(@yag_ays)まで気軽に声を掛けていただければと思います。
こういった勉強会は、これからも実施予定です。興味を持たれた方は、ぜひとも参加いただければと思います!
▼関連情報 未来の働き方に資するサービスを創り上げるAI技術者を募集
執筆者プロフィール
text:DSOC R&Dグループ 奥田裕樹