

はじめまして。2018年1月に入社した奥田(@yag_ays)です。
先日、scikit-learn-contribの1つであるCategory Encodersの最適化を実装したPull Requestがマージされたので、そこに至るまでのプロファイルや最適化の過程を紹介したいと思います。
普段、私の仕事は機械学習やデータ分析がメインで、あまりPythonの処理レベルで早いコードを書いたりすることはありません。もちろん最適化なんてことについては、あまり経験を持っていない素人なのですが、この記事が皆さんのプロジェクトを最適化する際の参考になれば幸いです。
tl;dr
- scikit-learn-contribの中のcategory_encodersの実行速度を最適化した
- Pythonのプロファイリングにはline_profiler、デバッグにはpdbが便利
- Pandasのカラムをfor文で書き換えるコードを書くことはやめよう
Category Encodersとは?scikit-learn-contribとは?
Category Encodersとは、カテゴリ変数をさまざまな数値の変数に変換するパッケージです。機械学習において特徴量を作成する際には、多くのアルゴリズムはカテゴリ変数をそのまま扱うことができず、何らかの量的変数に置き換えて表現する必要があります。
そういったカテゴリ変数の変換手法を実装したライブラリーがCategory Encodersです。One-Hot EncodingやBinary Encodingといった定番の変換手法はもとより、Target EncodingといったKaggleなどの分析コンペティションにおいても使われる手法が多数収録されています。
さて、このCategory Encodersはscikit-learn-contribプロジェクトの1つに登録されています。scikit-learnは、Pythonで最も有名な機械学習のライブラリーですが、そのscikit-learnのAPIの流儀に従って実装されたライブラリー群がscikit-learn-contribです。本家ほどの知名度や利用者こそないものの、ニッチなアルゴリズムや本家ではできない実験的なコードが収録されています。
なんか遅くない……?
ことの発端は、仕事で新しく扱い始めたデータを加工しているときでした。数千レコードくらいのそれほど多くないデータセットだったのですが、Category EncodersでOne-Hot Encodingするのになんと1分近くかかるのです!
One-Hot Encodingのアルゴリズム自体がそんなに重いわけはないだろうと本家scikit-learnの似た機能で試してみると、当然ながら1秒以内に終わります。データ量であったり、エンコーダーに受け渡すデータ形式まで疑ったりしたのですが、何ら問題はなく、あれこれと考えるうちにたどり着いたのが、カテゴリー変数に含まれるカテゴリーの種類数でした。
どうやらカテゴリー変数に含まれるカテゴリーの種類が多くなると、処理が極端に重くなるようです。手元で簡単なコードを書いてみると、確かにカテゴリー数が少ないと一瞬で終わる処理がカテゴリー数を少し増やしただけで、途端に重くなってしまいました。
そのときの状況を擬似的なコードで表すと、以下のような感じです。
import category_encoders
# sample data
num_category = 1000
many_categories_list = ["category_{}".format(i) for i in range(num_category)]
encoder = category_encoders.OneHotEncoder()
encoder.fit(many_categories_list)
ここではサンプルのデータとしてmany_categories_listという変数に、カテゴリー数がちょうど1000個になるようなリストを作成しています。実際に上記コードを回してみると、カテゴリー数が5や10くらいだと問題ないのですが、1000や10000で試すと処理が重くなることを確認できました。
この問題に直面した当初は「もうCategory Encodersは使わずに、他のライブラリーを使うか、自分がスクラッチで書くか」と思っていたのですが、Category Encodersが便利なライブラリーであることには変わりなく、今後のことを考えると使わないという選択肢が惜しいことから、仕事を終えてから原因究明に取り掛かることにしました。
実行が遅い箇所をプロファイルする
まずはおもむろにコードを眺めますが、私はウィザードではないのでライブラリーの中のどのコードが遅いのか、検討がつきません。そこで「推測するな、計測せよ」という教えに従い、Category Encodersの処理の中でどの部分がボトルネックになっているのかを突き止めます。
がむしゃらに1行ずつコードを動かして確かめるのも一つの手ですが、Pythonにはさまざまなプロファイラーが存在します。そもそものコードの実行時間を図るtimeであったり、cProfileといった多機能なプロファイラーが標準で実装されていたりしますが、いろいろと試す中で今回はline_profilerというプロファイラーを利用しました。
line_profilerは、コードの行単位で実行時間や実行ステップ数などがプロファイリングできるライブラリーです。今回は、IPythonで利用できる%lprunというマジックコマンドを利用しました。
%load_ext line_profiler
%lprun -f category_encoders.OneHotEncoder.fit category_encoders.OneHotEncoder().fit(many_categories_list)
これを実行すると、以下のような結果が出力されます。
ここでは注目すべき部分だけを抜き出して表示していますが、実行結果にはcategory_encoders.OneHotEncoder.fitのコード全体が表示されています。また、各カラムの意味は左からLine #, Hits, Time, Per Hit, % Time, Line Contentsとなっています。

これを見ると、どうやらOneHotEncoder.fit()が遅いのは、その内部で呼ばれているOrdinalEncoderという別のクラスが原因のようです。それでは、再度line_profilerを使って、今度はOrdinalEncoder.fit()の中身をプロファイルしてみましょう。
%lprun -f category_encoders.OrdinalEncoder.fit category_encoders.OrdinalEncoder().fit(many_categories_list)

今度は、OrdinalEncoder.fit()ではなく同じクラスに実装されているOrdinalEncoder.ordinal_encoding()の呼び出しに時間がかかっています。ここまで来ると、後は同じことの繰り返しです。ordinal_encoding()のプロファイルを取りましょう。
%lprun -f category_encoders.OrdinalEncoder.ordinal_encoding category_encoders.OrdinalEncoder().fit(many_categories_list)

ようやく見つけました! この273行と274行のPandasのコードが、category_encoders.OrdinalEncoder().fit(many_categories_list)という1行の処理全体について処理時間の99%を占めていることが判明しました。ここが遅いために、この箇所を呼び出しているOne-Hot Encoding自体も遅くなっていたんですね。
動作が重い箇所の2カラム目にある実行回数を見てみると1000と表示されており、プロファイルで指定したカテゴリー数の1000と同じであることから、ここのコードはカテゴリーの数だけfor文が呼ばれていることが推測できます。
修正のためにデバッグする
さて、Category Encodingsの中で処理が遅い部分が特定できたので、今度はこの箇所を最適化して何とか実行時間を短くしなければいけません。しかし、私はこのパッケージの作者ではないので、このクラスの変数categoriesに何が格納されているのか、変数Xは何を示しているのか、すぐには理解できません。
そこで、デバッグのためにpdbという標準パッケージを利用します。
まずは、デバッグしたいOrdinalEncoderのクラスのコードをそのままコピペして、テスト用のソースコード(ここではslow.pyとする)を用意し、そのクラスの中で処理の重い行の手前にブレークポイントを設定します。この状態で実行することで、ブレークポイントまで処理が進んだ状態で一旦実行が停止され、そこからは対話形式で1行ずつ処理を進めたり、各種変数の値を確認したりすることができます。
ここでもIPython上でpdbを動かすことができるipdbを使います。
# slow.pyのOrdinalEncoderクラスの一部
categories = [x for x in pd.unique(X[col].values) if x is not None]
X[str(col) + '_tmp'] = np.nan
import ipdb; ipdb.set_trace() # here
for idx, val in enumerate(categories):
X.loc[X[col] == val, str(col) + '_tmp'] = str(idx)
挙動を確認するのがデバッグの目的であり、プロファイリングのときのようにそれほど多くのカテゴリー数は必要ないので、カテゴリー数が4つのリストをサンプルデータにしました。
# slow.pyの実行部分
category_list = ["a", "b", "c", "a"]
encoder = OrdinalEncoder()
encoder.fit(category_list)
それではコードを実行してみましょう。すると、下記のように対話型のIPythonの画面が表示されます。出力されているコードを見ると、今は274行目まで実行が完了し、現在275行目のfor文で処理が停止していることが分かります。
$ python slow.py
> /Users/okuda/dev/github/categorical-encoding_orig/slow.py(275)ordinal_encoding()
274 import ipdb; ipdb.set_trace()
--> 275 for idx, val in enumerate(categories):
276 X.loc[X[col] == val, str(col) + '_tmp'] = str(idx)
ipdb>
続いては、この状態で登場する変数の確認です。普段、IPythonを利用しているときと同じく、変数名だけを入力してリターンキーを押すと、その変数の中身を表示してくれます。categoriesにはカテゴリーの種類が、Xにはカテゴリーのリストに加えて、_tmpという行が新しく追加されていることが分かりました。
ipdb> categories
['a', 'b', 'c']
ipdb> X
0 0_tmp
0 a NaN
1 b NaN
2 c NaN
3 a NaN
ここでは、for文は何をしているのでしょうか。pdbではnコマンドを入力するごとに、1行ずつ次のコードを実行することができます。for文を1回実行するために、2回nコマンドを入力し、改めてXの中身をのぞいてみましょう。
ipdb> X
0 0_tmp
0 a 0
1 b NaN
2 c NaN
3 a 0
何となく処理の内容がつかめましたね。どうやら、カテゴリー名に対応する数字を新しいカラムに追加しているようです。aというカテゴリーはcategoriesの中で一番先頭だったので、ここでは0が0行目と3行目に代入されています。このまま処理を進めると、1行目のbには1が、2行目のcには2が入りそうですね。実際にやってみると、確かにそのような結果となりました。
最適化
ここまでのプロファイリングとデバッギングを踏まえると、下記のようなことが分かりました。
ordinal_encoding()内部のfor文が異常に遅いこと- for文の中では、カテゴリごとに番号を割り振って新しいカラムに代入していること
- この部分を最適化すれば、処理時間を大幅に短縮できそうであること
次に問題となるのは、どうやってコードを修正するかです。こればかりは、経験と勘がものをいう世界かと思われるかもしれませんが、今回の場合はそうではありません。「Pandas for loop」みたいな感じでGoogle検索してみると、英語・日本語を問わず、多くの記事で「Pandasはfor文を使うと処理が遅くなる」と書いてあります。よくある落とし穴なんですね。修正の方法についても、丁寧に書かれている記事が多く公開されています。
そこで、今回はPandasのmap関数を利用して、列単位で「カテゴリー名aなら0、カテゴリー名bなら1……」といった操作を実装しました。細部は割愛しますが、問題点の最適化自体は下記のコード1行で済んでしまいました。
X[str(col) + '_tmp'] = X[col].map(lambda x: categories_dict.get(x))
この修正を踏まえて、いくつかのデータで実行した結果が元の実装のものと変わらないこと、Category Encodersのユニットテストを通して、最適化が問題ないことを確認しました。
なお、いくつかのPandasの高速化の記事を見ると、mapを使った別の書き方やNumpy Arrayを使ったベクトル化などで、より高速化を図れるような方法も紹介されていますが、今回はCategory Encodingsで実装されているコードとの整合性や可読性、修正箇所の少なさを優先して、上記の方法を採用しました。いろいろな部分を修正したくなる気持ちになりますが、1つの問題を解く際に他の問題を同時に解くことは望ましくありません。
最適化の結果
最後に、最適化によってどれくらい早くなったのか、処理時間を計測してみます。カテゴリー数が10、100、1000、10000の疑似データセットを作成して、元の実装と最適化後の実装、それぞれで処理を10回ずつ実行したときの平均処理時間を取ったのが、以下のグラフです。
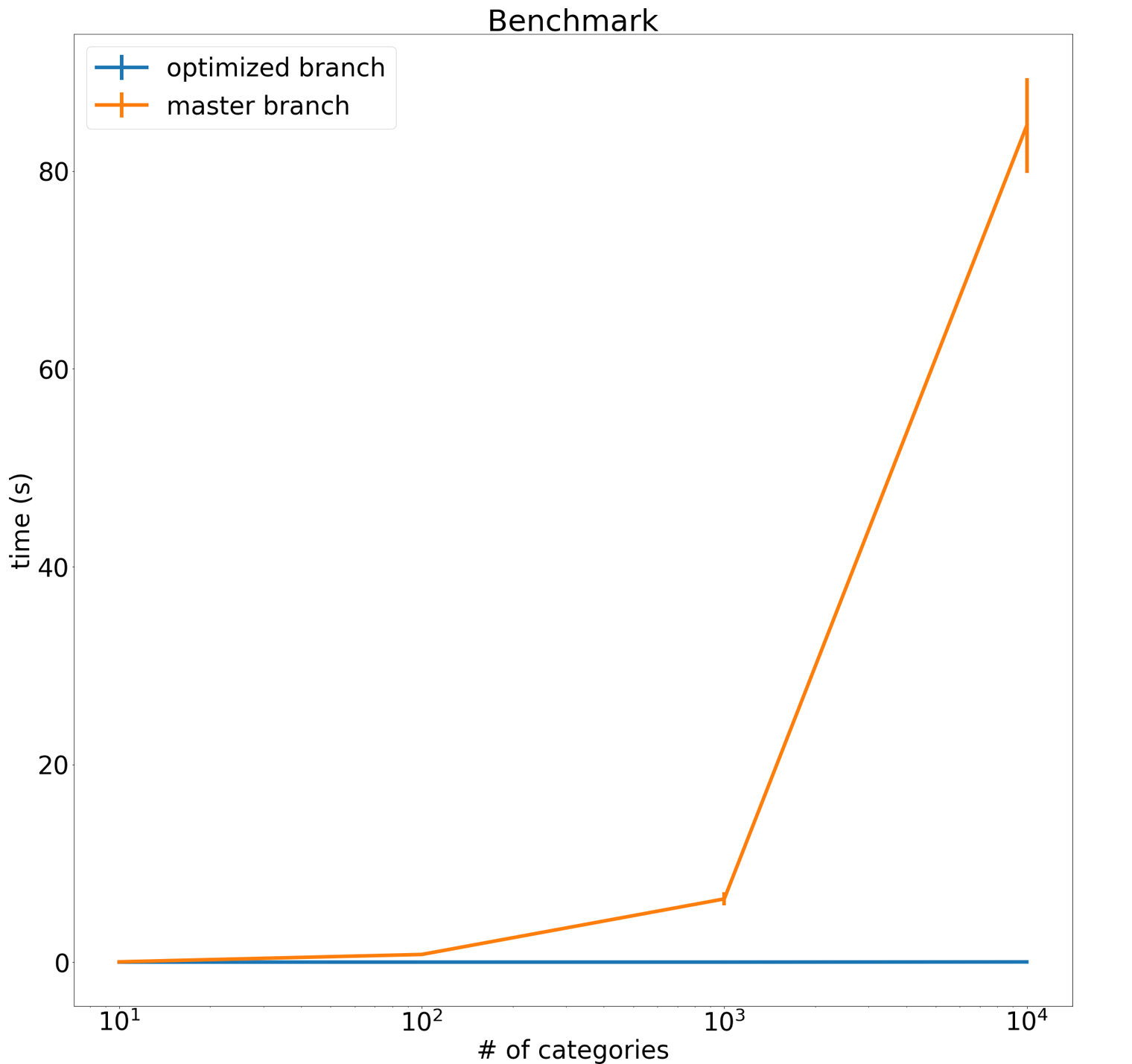
オレンジ色の線が元実装の処理時間、青色の線が最適化後の処理時間です。y軸のスケールが大きすぎて最適化後の処理時間がよく分かりませんが、とにかく大幅に短縮されていそうなことが分かります。実際に数字を見てみると、カテゴリ数10の場合では25ミリ秒→5ミリ秒と約5倍の高速化、カテゴリー数1000の場合に至っては85秒→0.025秒と約3400倍も高速化できていることが分かります。これで、大きなデータを処理する場合でも処理時間に悩む必要がなくなりそうです。
なお、ここで用いたコード全体は以下のgistから見ることができます。
https://github.com/scikit-learn-contrib/categorical-encoding/pull/58
Pull Requestと本体へのマージ
以上の結果を踏まえて、Category EncodersのGitHubからPull Requestを出し、無事にマージされました。
optimizing ordinal_encoding by yagays · Pull Request #58 · scikit-learn-contrib/categorical-encoding
2018年2月20日時点では、まだ公式アップデート前のためpipで更新することはできませんが、直接GitHubからインストールすることで試すことはできます。もしCategory Encodersの実行速度問題で悩んでいる方がいらっしゃれば、下記のコマンドで最新版をインストールして、試してみてください。
$ pip install git+https://github.com/scikit-learn-contrib/categorical-encoding
まとめ
いかがだったでしょうか? 今回は、Category Encodersというライブラリーを最適化する上での過程を紹介しました。こうやって書いてみるとあっさりしていますが、実際に試行錯誤しているときは、上手くいかないことばかりで結構大変でした。ただ、こうやって問題の発見から原因を突き止めて改善していくまでの一連の流れをプロファイリングやデバッギングの技術を駆使して解決していくことができたことは、とても良い経験になったと思います。この方法が最適化の全てではありませんが、もし何かのプロジェクトで最適化をしたいときには、参考にしていただければ幸いです。
執筆者プロフィール
text:DSOC R&Dグループ 奥田裕樹