
DSOC R&Dグループの中野良則です。
勾配ブースティングネタを連投してしまったので、今回はディープネタにしようと思います。テーマは変わりましたが、引き続き重箱の隅を突くような話になります。
背景
DSOC R&Dグループでは、月に一度、リモート勤務のメンバーも含めた全員が集まって勉強会を実施しています。
以前、このブログで紹介された「R&D論文読み会」と比べると、その勉強会ではそれぞれが自身の携わっているプロジェクトについて話すことが多いです。
そこで、多層パーセプトロンを使ったモデルについての報告がありました。私がロス関数として2乗誤差を使っていることに気が付いて質問したところ、「2乗誤差でも問題ないのではないか」という議論につながりました。
特に理由がないときは、Cross entropyかHinge lossを使うものだと考えていたので、その周辺について調査をしてみることにしました。
先行研究
新しいものとして、以下の論文を発見しました。
"On Loss Functions for Deep Neural Networks in Classification"
Katarzyna Janocha, Wojciech Marian Czarnecki. (2017)
Theoretical Foundations of Machine Learning 2017 (TFML 2017)
https://arxiv.org/abs/1702.05659
この論文では、むしろ「Cross entropyは好ましくなく、Squared Hinge lossを使うのが良い」と述べられていました。
他にもラベルにノイズがあるケースで、Cross entropyよりもMAEの性能が良いことを理論的・数値的に示した研究がありました。
"Robust Loss Functions under Label Noise for Deep Neural Networks"
Aritra Ghosh, Himanshu Kumar, P.S. Sastry. (2017)
The Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17)
https://arxiv.org/abs/1712.09482
数値実験
厳密な検証をするためには学習率などを吟味しないといけませんが、とりあえず簡素な追試を試みました。
ここでは、手書き文字認識データMNISTを利用しました。ネットワークや学習用パラメーターはTensorFlowのチュートリアルを参考にしました。
ロス関数は、以下のように定義しています。マルチクラス分類に対するロス関数は工夫の余地がさまざまにあるので(例えば「マルチクラスSVM」)、他の定義も考えられると思います。
# train_labels_node
# size: (BATCH_SIZE, )
# ラベルがインデックスで格納されている
# train_labels_hot_node
# size: (BATCH_SIZE, NUM_LABELS)
# train_labels_nodeをone-hotして格納されている
if loss_type == 'CE':
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=train_labels_node, logits=logits
)
)
else:
z = tf.multiply(train_labels_hot_node, tf.nn.softmax(logits))
if loss_type == 'MSE':
loss = tf.losses.mean_squared_error(
train_labels_hot_node,
z
)
if loss_type == 'MAE':
loss = tf.losses.hinge_loss(
train_labels_hot_node,
z
)
MSEやMAEのケースで勾配が小さくなるため、学習率を大きく取る方が公平な比較になると思われますが、ここでは調整しません。
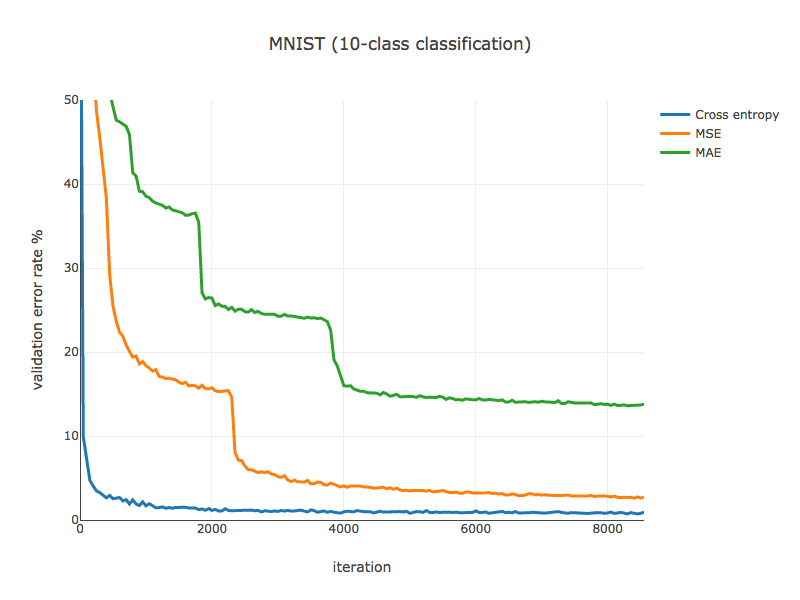
バリデーションデータに対するエラー率の推移は、以下のようになりました。
Cross entropyと比べると他の収束スピードが遅く、特にMAEは深刻であることが伺えます。速度の面でも、精度の面でも、Cross entropyを使うのがリーズナブルであるように見えます。
マルチクラス分類におけるロス関数の定義がよろしくない可能を考慮して、偶数/奇数を判定する二値分類問題でも確認をしました。
結果は以下の通りです。
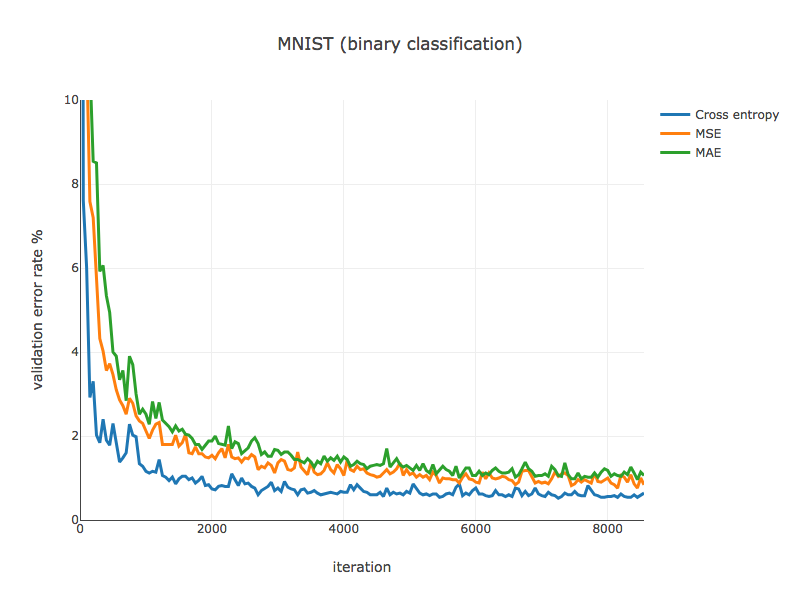
タスクが簡単になった分、MAEの精度も改善しましたが、やはり他と比べると収束スピードが気になります。ただし、二値分類問題の場合は出力層のユニット数を1にすることもできます。この場合であれば、収束スピードはそれほど問題にならないかもしれません。
まとめ
これまで何気なしにDeep Learningによる分類タスクにはCross entropyを使っていたのですが、収束のスピードや実装・チューニングの苦労から、それが正当化されることを確認できました。
ロス関数を工夫したとしても、ビルトインの関数から改善するのは大変そうです。
ネタに苦しみながらでしたが、今回で私の短期集中投稿はおしまいです。また報告できるような研究があった際には、改めてお会いしましょう。
リンク
執筆者プロフィール
text: DSOC R&Dグループ 中野良則