
お久しぶりです。DSOC R&Dグループの中野です。
今回は、機械学習界隈の皆さんが大好きなXGBoostの一機能とProbability calibrationについて調べたことを報告します。
背景
社内で解釈しやすい決定木について議論する機会があり、勾配ブースティングのライブラリーであるXGBoostでは単調性制約を加えることができることを紹介しました。その場では、「指定した上下関係が満足される分割の中でゲインを最大にするものが選ばれるんですよ」と解説したのですが、それでは不十分だったことを最近になって気が付きました。
以下のように身長から体重を予測する例を考えてみましょう。あくまでも模式図なので、実際にこのような分割が起こるかどうかは、気にせずに見てください。
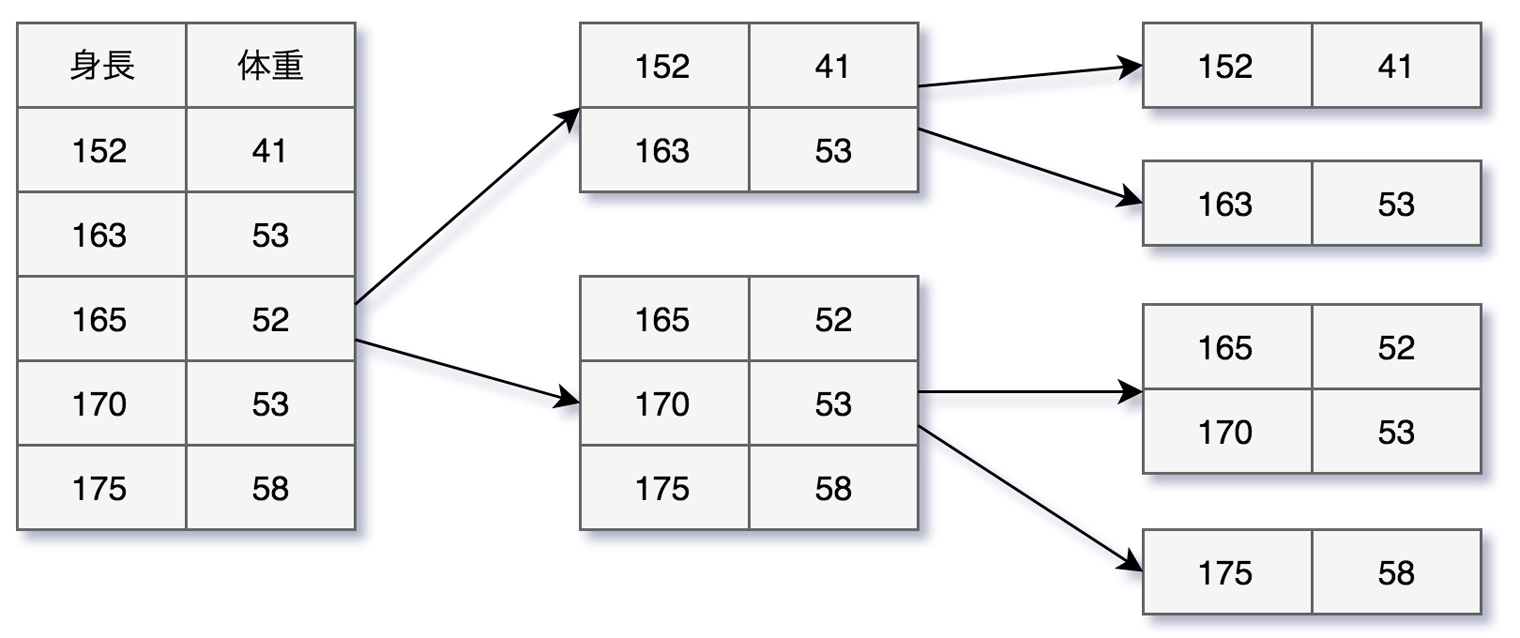
1回目の分割では、「身長が低く体重の軽い」グループと「身長が高く体重の重い」グループが抽出されています。
問題となるのは2回目の分割です。「身長が低く体重の軽い」グループ内の分割、「身長が高く体重の重い」グループ内の分割は単調性があるのですが、上から2番目のグループと3番目のグループで重みが逆転してしまいました。
さて、XGBoostではどのようにして単調性制約を実現しているのでしょう。
実装の確認
単調性制約は、 src/tree/param.h の ValueConstraint 構造体の中で実装されているようです。当該ヘッダーファイルには、指定された閾値でデータを分割したときのスコア計算についての処理が記述されています(※コード)。
CalcWeight メソッドに目的の処理が書かれています。
if (w < lower_bound) {
return lower_bound;
}
if (w > upper_bound) {
return upper_bound;
}
return w;
lower_bound, upper_bound でノードに割り当てる重みを制限しているようです。これらの上限・下限は、少し下の SetChild メソッドで設定されていました。
if (c == 0)
return;
/* 中略 */
if (c < 0) {
cleft->lower_bound = mid;
cright->upper_bound = mid;
} else {
cleft->upper_bound = mid;
cright->lower_bound = mid;
}
c == 0 は単調性制約なし、 c < 0 は特徴量に対してターゲットが単調減少する制約、 c > 0 は特徴量に対してターゲットが単調増加する制約に対応しています。
例えば c > 0 のケースでは、親のノードの重みの平均値を
- 特徴量の小さい子ノードに対する重みの上限
- 特徴量の大きい子ノードに対する重みの下限
として設定しています。
このような機構で分岐が深くなった場合でも単調性が保たれるようです。
実際にこの機能を利用するには、以下のようにパラメータを追加します。ここでは2列目の特徴量に対して単調増加、4列目の特徴量に対して単調減少としています。
param['monotone_constraints'] = '(0,1,0,-1,0)'
model = xgb.train(param, dtrain, num_round)
scikit-learnラッパーを用いる場合でも以下のように利用できます。
model = xgb.XGBClassifier(
monotone_constraints='(0,1,0,-1,0)'
)
model.fit(x_train, y_train)
キャリブレーションへの適用
ここまでXGBoostの単調性制約について確認してみましたが、そのような制約をかけるのは「解釈しやすくするため」という理由が多く、精度向上を目指してXGBoostを使っていることとはマッチしません。
真っ当な適用先としては、分類問題におけるキャリブレーションが挙げられます。勾配ブースティングやディープラーニングのような高次元の学習器は、学習データに対するロスを殆どゼロにできるので、モデルが出力する確率も0%か100%に近く自信過剰なものになります。テストデータに対して、当然ながらそこまでの精度を出せないため、対数損失などで評価する際には、キャリブレーションという調整が必要になることが知られています。
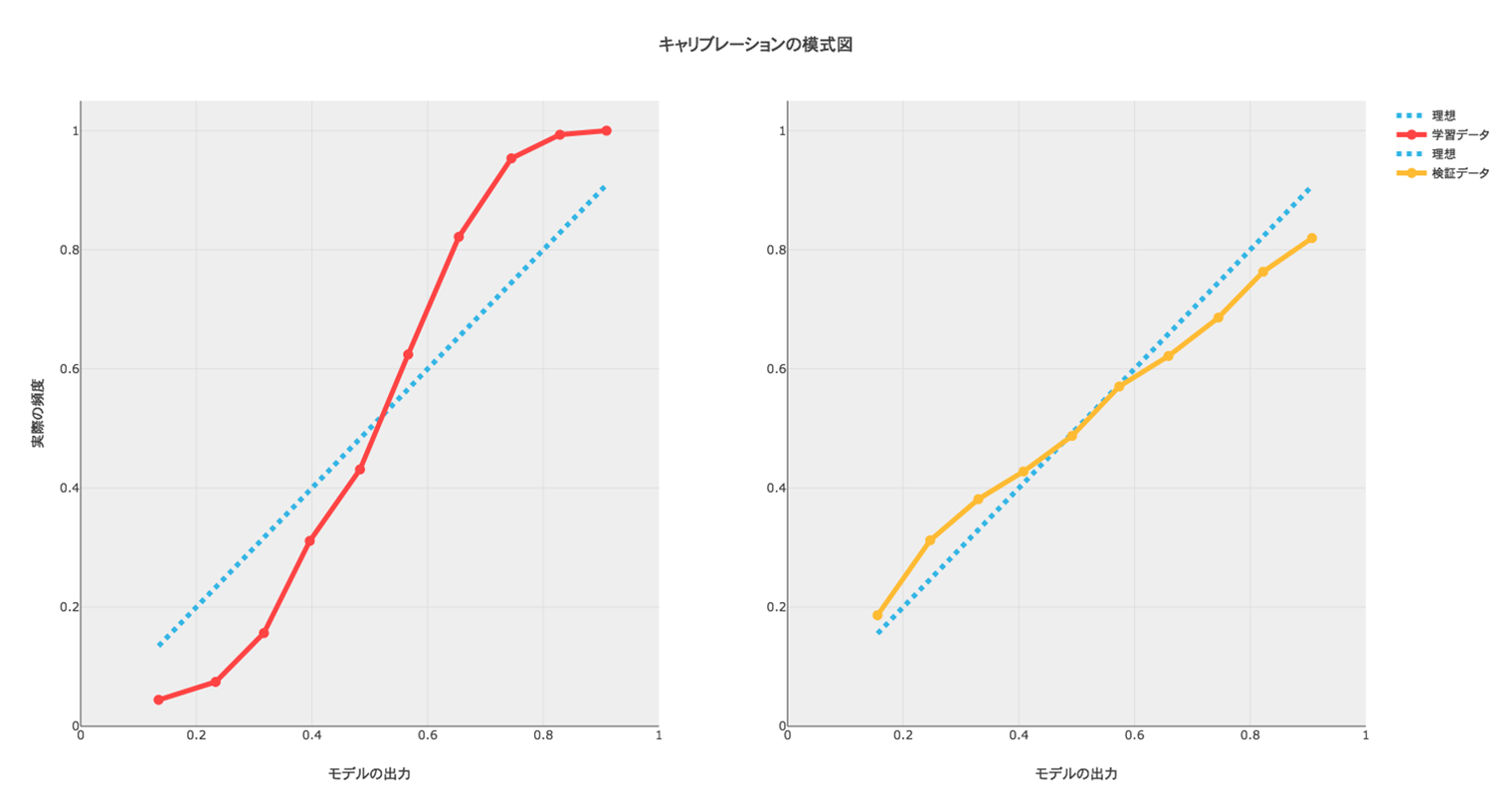
下の図において、モデルの出力と実際の頻度における関係が理想的な青色の線から乖離しているのを補正します。scikit-learnのドキュメントの絵を見ると、下の図中で左のグラフに似た図がありますが、われわれが関心があるのは汎化性能なので右のグラフ、つまり検証のデータに対して補正をするのが正しいようです。元のコードでも検証データを相手にしています。1
キャリブレーションをするのに手軽な方法としてscikit-learnにIsotonic regressionが準備されています。 このIsotonic regressionとXGBoostによるキャリブレーションを比較してみましょう。
Isotonic regressionのscikit-learnによる実装は2乗誤差最小化をしているため、キャリブレーションには不向きかもしれません。一方で、XGBoostは調整できるパラメーターが多いことがネックです。
今回は、Kaggle Porto Seguro's Safe Driver Predictionのデータを利用しました。コンペでは、Giniが評価基準だったためにキャリブレーションは不要でしたが、ここでは対数損失を見ることとします。
まずは、学習データ x_train, y_train を用いてベースのモデルを構築します。
clf = xgb.XGBClassifier(
max_depth=5,
learning_rate=0.05, n_estimators=500,
)
clf.fit(x_train, y_train)
次に、学習データとは別の x_valid, y_valid を使ってキャリブレーション用モデルを学習します。
p_valid = clf.predict_proba(x_valid)[:, 1]
# Isotonic regression
cal_iso = IsotonicRegression(out_of_bounds='clip')
cal_iso.fit(p_valid, y_valid)
# XGBoost
cal_xgb = xgb.XGBClassifier(
max_depth=3,
learning_rate=0.05, n_estimators=100,
monotone_constraints='(1)'
)
cal_xgb.fit(p_valid.reshape(len(p_valid), 1), y_valid)
ベースモデルの出力値とキャリブレーションした確率は、単調増加の関係になることが期待されるので monotone_constraints='(1)' としています。
さらに、別のデータセット x_test, y_test に対して対数損失を計算した結果が以下になります。
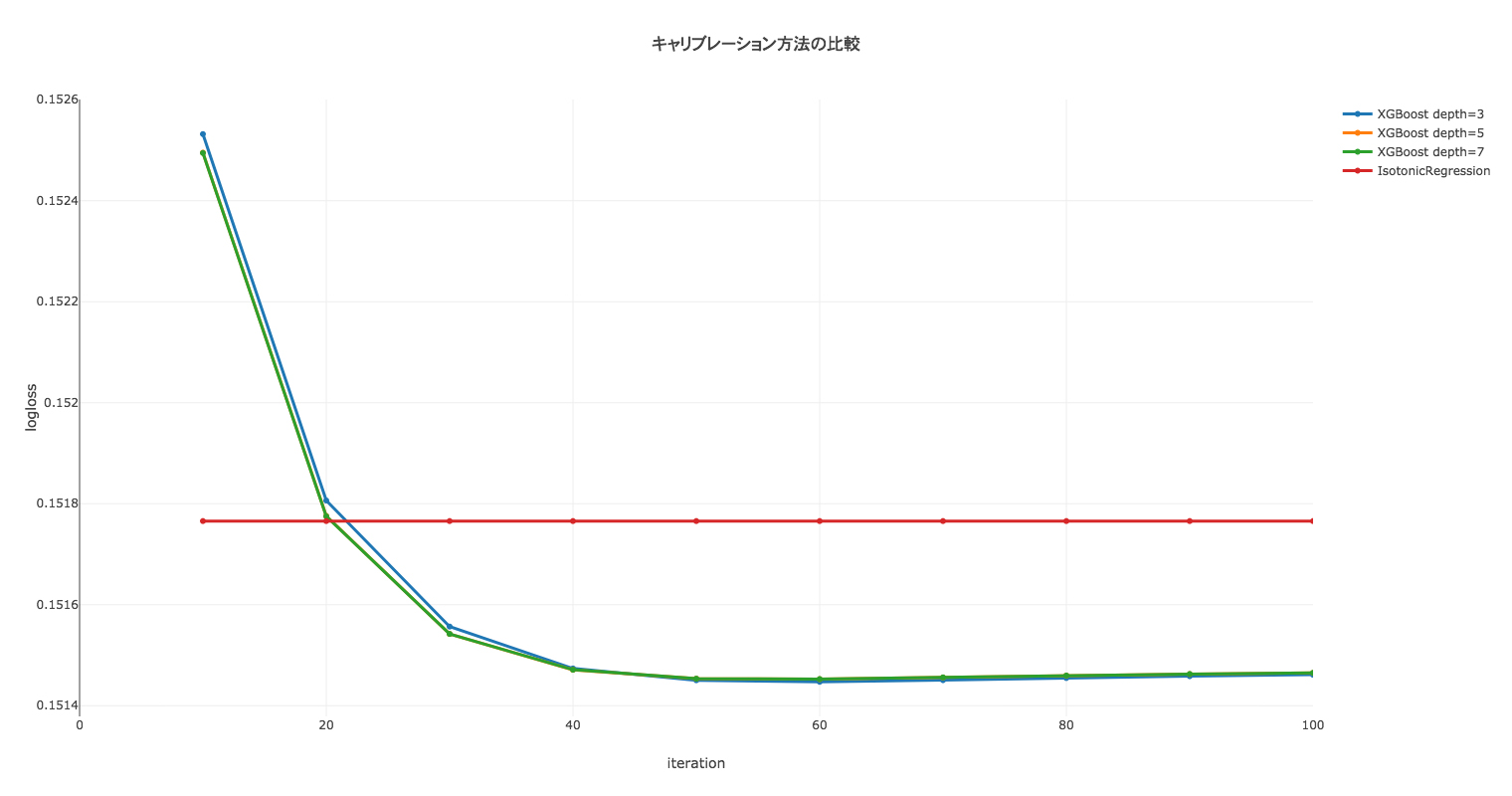
今回のケースでは、XGBoostの方がキャリブレーションの性能が良くなりました。単調性制約がかかっているので max_depth, n_estimators は大きめの値を設定して問題なさそうです。
不均衡データかどうか、ベースモデルの性能などの諸条件によってどちらのキャリブレーション方法の精度が良くなるか、変わる可能性があります。私が取り組んだ別のタスクにはIsotonic regressionの方が良好だったものもあるので、比較して使っていくのがベターかと思います。
リンク
-
XGBoostに関するもの
- XGBoost
- Monotonic constraints (XGBoost)
-
scikit-learnに関するもの
- Probability calibration (scikit-learn)
- IsotonicRegression (scikit-learn)
-
キャリブレーションに関係する諸々の記事
- 6 Tricks I Learned From The OTTO Kaggle Challenge
- 傾向スコアの調整(TJOさん)
執筆者プロフィール
text: DSOC R&Dグループ 中野良則
- 勾配ブースティングとRandom forestでカーブの凹み方が逆なのは、興味深いです。Random forestでは弱学習器を並列にまとめているので出力が丸くなりやすいようです。 ↩